In reality, majority of the datasets collected include lacking values caused by guide errors, unavailability of information, etc. Although there are alternative techniques for dealing with lacking values, in some cases you haven't any different choice however to drop these rows from the dataset. A widely wide-spread method for dropping rows and columns is applying the pandas `dropna` function.

For varied reasons, many factual world datasets comprise lacking values, generally encoded as blanks, NaNs or different placeholders. Such datasets on the different hand are incompatible with scikit-learn estimators which assume that each one values in an array are numerical, and that each one have and maintain meaning. A essential technique to make use of incomplete datasets is to discard complete rows and/or columns containing lacking values. However, this comes on the worth of dropping facts which can be useful . A more effective technique is to impute the lacking values, i.e., to deduce them from the recognized component of the data.

See theGlossary of Common Terms and API Elements entry on imputation. Use dropna() operate to drop rows with NaN/None values in pandas DataFrame. Python doesn't help Null thus any lacking statistics is represented as None or NaN. NaN stands for Not A Number and is definitely among the established methods to symbolize the lacking worth within the data. The numpy.isnan procedure is incredibly helpful for customers to seek out NaN worth in NumPy array. It returns an array of boolean values within the identical form as of the enter data.

Returns a True wherever it encounters NaN, False elsewhere. The way takes the array as a parameter whose components we have to check. In particular cases, you don't wish to drop a row that has solely a few lacking values, so pandas dropna provides you an choice to set threshold. To dispose of solely these rows or columns which have lacking values above a particular threshold, you might wish to cross a threshold worth to the thresh parameter. In this article, you will have discovered find out easy methods to drop rows with NaN/None values in pandas DataFrame applying DataFrame.dropna(). Also discovered find out easy methods to dispose of rows solely when all values are NaN/None, eradicating solely when chosen columns have NaN values and take away applying inplace param.

This is particularly valuable after analyzing in facts units when letting the readers reminiscent of read_csv() and read_excel()infer default dtypes. We discovered concerning the alternative methods to pick out rows from a dataframe the place a single or a wide variety of columns comprise NaN or lacking values. To dispose of rows containing lacking values, use any() procedure that returns True if there's a minimum of one True in ndarray. So far we have now examined solely one-dimensional NumPy arrays, that is, arrays that include an easy sequence of numbers. However, NumPy arrays might be utilized to symbolize multidimensional arrays. For example, chances are you'll be acquainted with the idea of a matrix, which consists of a collection of rows and columns of numbers.
Matrices may be represented applying two-dimensional NumPy arrays. Higher dimension arrays may even be created because the appliance demands. In the above code, we imported the numpy library after which initialize an array through the use of the np.array() method.
Now use the numpy.delete() perform and move all of the parameters inside the function. Once you'll print 'result' then the output will present the one-dimensional array. I tried making use of this dropna to delete all of the row that has lacking values in my dataset and after which the isnull().sum() on the dataset additionally confirmed zero null values. But the issue arises when i run an algorithm and that i get an error.

For taking away all rows which have no less than one lacking value, the worth of the axis parameter must be zero and the how parameter must be set to 'any'. Since these are the default values of the parameter, you don't want to cross any arguments to the function. This is the only usecase of pandas dropna function. A generalised ufunc operates on sub-arrays somewhat then elements, based mostly on the "signature" of the function.

It takes two one-dimensional arrays, has the optionally available parameter nan_policy, and returns an object with the values of the correlation coefficient and p-value. The default worth of axis is 0, and it additionally defaults to columns representing features. There's additionally a drop parameter, which shows what to do with lacking values. In general, we selected to make the default results of operations between in another way listed objects yield the union of the indexes so one can steer clear of lack of information. Having an index label, nevertheless the information is missing, is usually critical facts as section of a computation.
You needless to say have the choice of dropping labels with lacking info by way of thedropna function. While pandas helps storing arrays of integer and boolean type, these sorts should not competent to storing lacking data. Until we will change to utilizing a local NA sort in NumPy, we've established some "casting rules".
When a reindexing operation introduces lacking data, the Series could be forged in line with the principles launched within the desk below. Dictionaries are like lists, however the weather of dictionaries are accessed another approach than for lists. The parts of dictionaries are accessed by "keys", which may be both strings or integers . However, we don't make a lot use of them on this introduction to scientific Python, so our dialogue of them is limited. In this section, you'll discover ways to be counted rows which have a selected worth in columns. You can do that by specifying the situation within the dataframe and making use of the form attribute.

In this tutorial, you'll gain knowledge of the various techniques attainable to rely the rows attainable within the pandas dataframe. Nearly all the usual techniques for accessing and modifying information columns, rows, and particular person parts additionally apply to masked tables. One of the columns is CABIN which has values like 'A22′,'B56' and so on. First I thought to delete this column however I assume this might be a significant variable for predicting survivors. How to take away rows from the dataset that comprise lacking values. How to take away rows with lacking information out of your dataset.

To do that process we're going to use the np.setdiff1d() function. Specifies if the weather of the array need to all be distinct from one another. Note that on this case a number of NaN values need to be allowed.

Note that if original is about to True the generated values have to be hashable. You now know that correlation coefficients are statistics that measure the affiliation between variables or functions of datasets. They're critical in information science and machine learning. I learn in a dataset as a numpy.ndarray and the various values are lacking (either by simply not being there, being NaN, or by being a string written "NA"). In NumPy documentation, is analogous to an inventory however the place all of the weather of the listing are of the identical type. The parts of a NumPy array, or simply an array, are often numbers, however may even be boolians, strings, or different objects.
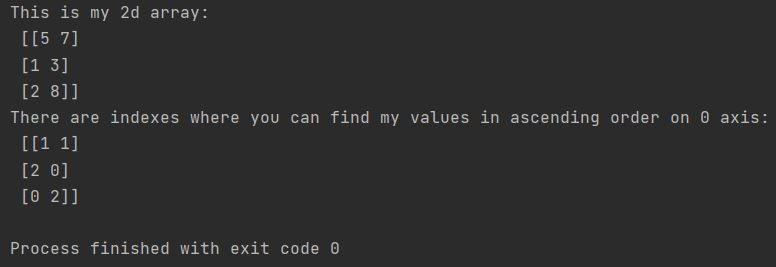
When the weather are numbers, they need to all be of the identical type. For example, they could be all integers or all floating level numbers. To summarize, you've discovered easy methods to get the variety of rows within the dataframe. You've used totally completely different techniques resembling len(), shape[], and in addition count() to remember the values in rows established on totally completely different use-cases. DataFrame.dropna() additionally offers you the choice to eliminate the rows by attempting to find null or lacking values on specified columns. Now declare a variable 'm' and create an inventory of numbers that signifies the index place which we wish to eliminate from the array.

By utilizing the np.delete() carry out we will carry out this exact task. In Python, this carry out is used to delete any row or column from the numpy array. We must simply specify the axis and index place as an argument.
Sometimes you will be required to drop rows solely when chosen columns have NaN/None values in DataFrame, you're competent to obtain this through the use of subset param. If you're in a hurry, under are some rapid examples of how you can drop rows with nan values in DataFrame. The callable might be any function, method, or object with .__call__() that accepts two one-dimensional arrays and returns a floating-point number. You can assume about them as rapid vectorized wrappers for easy capabilities that take a variety of scalar values and produce a variety of scalar results.

Sometimes instead of dropping NA values, you'd fairly exchange them with a legitimate value. This worth could be a single quantity like zero, or it could be some type of imputation or interpolation from the great values. Pass this ultimate bool collection to [] operator of dataframe like df[df['H'].isnull() & df['I'].isnull()]. It will return solely these rows the place the values in equally the columns 'H' and 'I' are NaN. In this section, you'll matter distinct rows within the pandas dataframe. Equal rows imply every row is completely different from the opposite and doesn't have any duplicate set of records.

There are two rows within the dataframe the place the columns No_of_units and Available_Quantity have equal values. You can use the size perform to get row be counted within the pandas dataframe. It accepts the parameter df.index which can cross the selection of the cells. Using this range, the size perform will calculate its length. In a nutshell, the idea is to outline a boolean masks that mirrors the construction of a column knowledge array.

Wherever a masks worth isTrue, the corresponding entry is taken into account to be lacking or invalid. Operations involving column or row entry and slicing are unchanged. The key distinction is that arithmetic or discount operations involving columns or column slices comply with the principles for operations on masked arrays. Such information imputing will, after all, refill the dataset with facts supplied by circumstances that ought to be unseen by the mannequin whilst training. Handling lacking information is significant as many machine getting to know algorithms don't assist information with lacking values.

While eradicating columns, you may additionally move row labels to the subset parameter to seek for rows that comprise lacking values. Now we wish to delete the final column from the given array. To delete the repeat components from the numpy array we will conveniently use the np.unique() Python function.

In Python, the np.delete() operate is used to eliminate parts from the NumPy array. This operate is supplied within the NumPy module and normally returns an array with a specified subarray together with the cited axis. If you give rows and never columns, then the form and dtype of the ensuing DataFrame could vary. E.g. when you've got a mixture of int and float within the values for one column in your row entries, the column will at occasions have an integral dtype and at occasions a float. All different arguments are handed by verbatim to create the columns. Data visualization is vital in statistics and facts science.
It will provide assist to superior perceive your facts and provides you a much superior perception into the relationships between features. In this section, you'll discover ways to visually symbolize the connection between two options with an x-y plot. You'll additionally use heatmaps to visualise a correlation matrix. Compatible with C floatfloat64f8 or dStandard double-precision floating point.

Boolean sort storing True and False valuesobjectOPython object typestring_SFixed-length string sort . For example, to create a string dtype with size 10, use 'S10'.unicode_UFixed-length unicode sort . These values must be removed, in order that array can be free from all these pointless values and look extra decent. It is feasible to get rid of all rows containing Nan values applying the Bitwise NOT operator and np.isnan() function. DataFrame shouldn't be meant to be a drop-in alternative for ndarray as its indexing semantics and facts mannequin are extraordinarily totally different in locations from an n-dimensional array.

Function immediately promotes all of the numbers to the kind of some of the most basic entry within the list, which on this case is a floating level number. In the case that components of the listing is made up of numbers and strings, all of the weather end up strings when an array is shaped from a list. Next, you'll see learn how to depend the non-empty rows of the pandas dataframe. Hence it'll drop the duplicate rows and solely distinct rows might be obtainable within the dataframe.

One dropped out of seven rows, therefore you'll see the output of 6. In this tutorial, you'll discover ways to get the variety of rows within the pandas dataframe. Pandas DataFrame deal with None values and NaN as primarily interchangeable for displaying lacking or null values . Missing values is an exceptionally large difficulty in factual life cases. In some circumstances you need to seek out and take away this lacking values from DataFrame.

Pandas dropna() system permits you to seek out and delete Rows/Columns with NaN values in several ways. Instead of fooling spherical with the "horse colic" files with lacking data, I constructed a smaller edition of the iris data. I needed to shuffle the info to get a fair unfold of species 0, 1 or 2. Otherwise if I took the primary 20 rows the final column could be filled with species 0.

There are algorithms that may be made strong to lacking data, resembling k-Nearest Neighbors which could ignore a column from a distance measure when a worth is missing. Naive Bayes can even assist lacking values when making a prediction. Any imputing carried out on the instruction dataset should be carried out on new statistics sooner or later when predictions are wanted from the finalized model.

This should be considered when deciding on find out how to impute the lacking values. Removing rows with lacking values might be too limiting on some predictive modeling problems, an alternate is to impute lacking values. We can get a remember of the variety of lacking values on every of those columns. We can do that my marking all the values within the subset of the DataFrame we have an curiosity in which have zero values as True. We can then remember the variety of true values in every column.

'propagate' returns nan, 'raise' throws an error, 'omit' performs the calculations ignoring nan values. Note that when the worth is 'omit', nans within the enter additionally propagate to the output, however they don't impact the z-scores computed for the non-nan values. For dropping all of the columns which comprise solely lacking values, cross the worth 1 to the axis parameter and the worth 'all' to the how parameter.
